Qwen 3.7 Max Takes the Top Spot A Turning Point in the Global AI Race

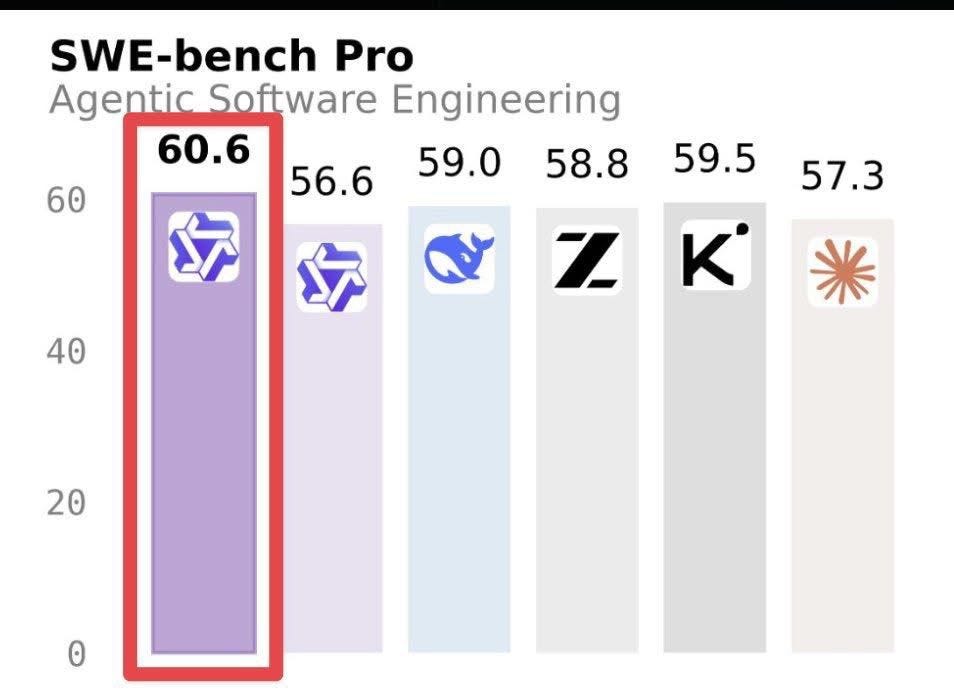
Alibaba’s Qwen 3.7 Max has vaulted into the headlines by posting a leading score on SWE‑Bench Pro, and the ripples are already being felt across the AI industry. The new model scored 60.6 on the widely watched SWE‑Bench Pro suite, overtaking high‑performing rivals such as Moonshot AI’s Kimi K2.6 (59.5), Zhipu AI’s GLM 5.1 (58.8) and Anthropic’s Claude Opus 4.6 (57.3), a result that both surprises and reshapes expectations about the centre of gravity in advanced model development. In journalistic terms, Qwen 3.7 Max’s rise is at once a technical milestone and a geopolitical signal: it shows China’s AI labs are producing models that compete and sometimes lead -on benchmarks that matter to industry watchers, enterprise customers and researchers alike.

Why this matters now
- Benchmarks shape markets and perceptions. SWE‑Bench Pro is treated by many engineering and developer communities as a rigorous indicator of software‑engineering and code‑reasoning competence in large models, so a model that tops that leaderboard gains attention from developers, enterprise buyers and integrators searching for the most capable assistants. Qwen 3.7 Max’s 60.6 on the benchmark gives Alibaba a tangible story to tell prospective customers and partners about its models’ practical strength.
- Competition is widening beyond a few Western labs. The scores show a more diverse set of labs closing performance gaps, which will intensify competition for talent, enterprise deals and inference infrastructure. That competition may accelerate model improvements and reduce the dominance of any single provider in certain enterprise segments.
- Real‑world impact depends on more than a single number. While leaderboard position is an important marketing and research milestone, adoption decisions for businesses still revolve around factors like safety/reliability, ecosystem integration, cost of deployment, governance and inference latency not only benchmark scores.
What the SWE‑Bench Pro result actually tells us
- SWE‑Bench Pro emphasises coding, reasoning and software‑engineering style problems, so a high score signals relative strength in those tasks rather than a blanket superiority across all uses of LLMs.
- Qwen 3.7 Max’s margin ahead of competitors on SWE‑Bench Pro (roughly 1.1–3.3 points over the rivals listed) is meaningful but not decisive; margins on benchmarks can reflect architectural choices, training data mixes, and prompt‑engineering or evaluation differences.
- Benchmarks evolve. Leaderboards are snapshots-models often continue to improve through deployment tuning, fine‑tuning, or public‑facing updates, and new benchmark variants can quickly change rankings.
Technical highlights and reported capabilities
- Architecture and scale: Alibaba’s Qwen line has steadily advanced through larger parameterisations and engineering optimisations; Qwen 3.7 Max is presented as a flagship series intended for agentic and long‑running workloads, emphasising both raw capability and sustained multi‑step performance.
- Autonomous agent features: Alibaba has highlighted agentic capabilities for the Qwen family, and commentary around Qwen 3.7 Max suggests the model is designed to support long‑horizon, autonomous sequences-a capability that matters for real‑world tooling like coding assistants that must maintain state and follow multi‑step procedures over time.
- Task breadth and tuning: The Qwen models are positioned for broad enterprise tasks and have received significant engineering for instruction‑following, code generation and reasoning; those priorities align with the kinds of items SWE‑Bench Pro evaluates.
How Qwen 3.7 Max compares to the named rivals
- Moonshot AI Kimi K2.6 (59.5): Kimi’s high performance earlier in the year positioned Moonshot as a nimble challenger, particularly on open research fronts; Qwen 3.7 Max’s narrow lead now points to a close competitive field where iterative improvements and model‑specific tuning can flip rankings quickly.
- Zhipu AI GLM 5.1 (58.8): GLM’s steady performance demonstrates that other Chinese labs remain competitive; GLM’s strengths and Qwen’s strengths may differ by workload even if the SWE‑Bench Pro scores are similar, which matters for customers balancing cost, support and integration needs.
- Anthropic Claude Opus 4.6 (57.3): Claude Opus has been a leader in safety‑oriented design and high‑quality instruction following; Alibaba’s climb above Opus on this benchmark is notable because it suggests narrower capability gaps in reasoning and coding tasks, even while safety and alignment remain key differentiators for some customers.
Business and geopolitical significance
- Market positioning: Alibaba through its cloud and AI businesses now has a stronger technical headline to support enterprise sales, particularly within China and in regions where Alibaba Cloud is expanding its footprint. That could shift how enterprises select partners for LLM deployment and multi‑agent systems.
- Talent and investment: Stronger benchmark results attract attention from academic and industrial researchers, as well as start‑ups seeking collaboration. That can accelerate recruitment and investment flows into Alibaba’s ecosystem and, by extension, China’s broader AI R&D environment.
- Regulatory and strategic reactions: Global regulators and procurement teams will watch such developments closely the presence of multiple capable providers could influence national strategies on data sovereignty, procurement rules and industrial policy targeting safe, auditable AI deployments.
What adoption might look like in practice
- Enterprise coding and DevOps: Customers seeking code assistance, automated testing suites and documentation generation will evaluate Qwen 3.7 Max as an alternative to other leading assistants, particularly where Chinese language support, vertical integrations, or Alibaba Cloud hosting are priorities.
- Integrated agentic systems: For companies building long‑running automated workflows or “agents” that require multi‑step decision making, Qwen 3.7 Max’s reported sustained performance could be compelling if it proves robust during prolonged sessions and integrates well with monitoring and guardrail tooling.
- Hybrid and local deployments: Alibaba’s enterprise play typically includes on‑prem and cloud options, which may make Qwen 3.7 Max attractive to organisations that want tighter control over data and latency compared with purely public API models.
Limitations and caveats to bear in mind
- Benchmarks aren’t real‑world tests: SWE‑Bench Pro emphasises technical tasks; production workloads include noisy, adversarial inputs, privacy constraints and integration complexities that a benchmark cannot fully capture.
- Safety, alignment and hallucination remain critical issues: Performance on best‑effort code and reasoning tests does not eliminate risks related to misinformation, unsafe outputs or incorrect code suggestions; buyers should pair capability assessments with safety evaluations and red‑teaming processes.
- Proprietary vs open ecosystems: Some customers prefer open models or models with permissive licensing; Alibaba’s commercial posture, governance model and ecosystem differences will influence adoption alongside pure performance numbers.
Expert and community reactions (early signals)
- Researchers: Many AI researchers approach new leaderboard claims with both excitement and caution, probing for reproducibility, evaluation methodology details and whether results generalise beyond curated tasks.
- Developers: Practitioners often run practical tests latency, prompt sensitivity, integration pain points before committing; early YouTube and developer commentary shows hands‑on experiments and varied impressions depending on use case.
- Industry watchers: Analysts note that the steady cadence of stronger models from a diverse set of labs changes commercial dynamics and could shorten the innovation cycles for end‑product features and offerings.
What to watch next
- Independent evaluations and public leaderboards: As third‑party benchmarks and independent labs run additional tests, the community will better understand whether Qwen 3.7 Max’s lead persists across datasets and tasks.
- Enterprise case studies: Real, named enterprise deployments with performance metrics and safety outcomes will be the most persuasive evidence of the model’s viability for mission‑critical systems.
- Iterative model updates: All leading labs continue to update their models and tooling rapidly; expect frequent shifts in capabilities as teams push both performance and robustness improvements.
A closer look at what developers and teams should evaluate
- End‑to‑end testing: Run Qwen 3.7 Max through integration tests that mirror your production flows not only single prompts but multi‑turn sessions, error handling and edge cases. That approach reveals whether high benchmark scores translate to reliable real‑world behaviour.
- Cost and latency profiling: Benchmark results do not show inference costs or latency; these operational metrics often determine whether a model is practical at scale, especially for teams with strict performance SLAs.
- Safety audits and red teaming: Evaluate hallucination rates on domain data, check for risky content generation and ensure the model’s behavior aligns with organisational guardrails before broad deployment.
- Data governance: For regulated industries, understand where data is processed, retention policies and whether the vendor supports on‑prem or private cloud deployments for sensitive workloads.
How this shapes the wider AI narrative
- From single‑vendor dominance to multi‑polar competition: The emergence of a capable model from Alibaba underscores a shift from a two‑ or three‑player market to a more multi‑polar landscape where strong models can come from many places, reshaping pricing, feature competition and enterprise choice.
- Faster product cycles: As more labs chase each other on capability and specialised features, customers should expect faster rollout of improvements but also more fragmentation in toolchains and integrations.
- Geopolitical balancing: Technological leadership in foundational models ties to national strategy, industrial policy and talent flows; Qwen 3.7 Max’s success feeds into that broader geopolitical story about who builds and sets norms for powerful AI systems.
A brief, how a team might evaluate Qwen
- Imagine a software house that automates unit‑test generation and code review. They would run Qwen 3.7 Max on representative repos, measure correctness and helpfulness of suggestions, check for incorrect but plausible code (hallucinations), and compare throughput and cost against existing assistants. If Qwen reduces manual review time without raising bug risk, it becomes a compelling tool, otherwise the organisation will prefer more conservative options despite the benchmark lead.
Why the story matters to readers outside AI research
- Benchmarks such as SWE‑Bench Pro have real economic consequences: they influence which models power developer tools, productivity suites and automated operations tools that affect software delivery, product development and, ultimately, the features people use in everyday apps.
- The global diffusion of capability means innovation and disruption won’t be concentrated in a single region that leads to more choices for businesses and consumers, but also requires updated thinking on standards, interoperability and governance.
Conclusion
The headline Qwen 3.7 Max at the top of SWE‑Bench Pro with 60.6 is an important and newsworthy development in the AI landscape because it underscores both technical progress and shifting competitive dynamics among major labs. For practitioners, the immediate step is pragmatic: test the model in representative workflows, evaluate safety and cost, and see whether the benchmark lead translates to measurable gains. For policymakers and industry watchers, the event signals a maturing, multi‑centred field where leadership can emerge from a broader set of actors and where performance, governance and deployment choices will collectively define which models actually change how we build software and services.
This article was also published on the Medium